



This post is cross-posted from James Aimonetti’s personal blog.
While writing a bulk importer for Crossbar, I took a look at squeezing some performance out of BigCouch for the actual inserting of documents into the database. My first time running all the documents into BigCouch at the same time resulted in some poor performance, so I went digging around for some ideas on how to improve the insertions. Reading up on the High Performance Guide for CouchDB (which BigCouch is API-compliant with), I started to play with chunking my inserts up to get better overall execution time.
Note: The following are very unscientific results, but I think they’re fairly instructive for what one might expect.
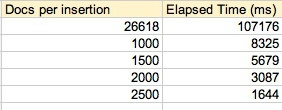
Based on the CouchDB guide, I decided to not pursue this further, as dropping insertion time 2 orders of magnitude was fine enough for me! I may have to bake this into the platform natively.
For those interested in the Erlang code, it is pretty simple. Taking a list of documents to save, use lists:split/2 to try and split the list. By catching the error, we can know that the list is less than our threshold, and can save the remaining list to BigCouch. Otherwise, lists:split/2 chunks our list into one for saving, and one for recursing back into the function. Since we don’t really care about the results of couch_mgr:save_docs/2, we could put the calls in the second clause of the case in a spawn to speed this up (relative to the calling process).